Entre nous, vous n'en avez pas un peu marre d'entendre des phrases de types "Je veux un usage d'IA par mois !", ou "Posez-moi un serveur MCP ! Pourquoi faire ? Je sais pas, mais il en faut...", ou "T'as vu le dernier modèle de chez OpenMistropic ? J'ai pu refaire mon application en 2h, alors qu'il m'a fallu 3 ans pour arriver à ma première version stable avant ça !". Bref...
Néanmoins, en tant qu'architecte, on doit se poser la question : comment construire quelque chose de solide quand les fondations technologiques changent toutes les trois semaines ? Et la réponse n'est pas forcément simple...
Mais, avant de choisir le moindre outil, posez-vous ces trois questions (merci à Une année difficile pour l'inspiration😉)
- Ai-je besoin d'IA ?
- Ai-je vraiment besoin d'IA ?
- Ai-je vraiment besoin d'IA maintenant ?
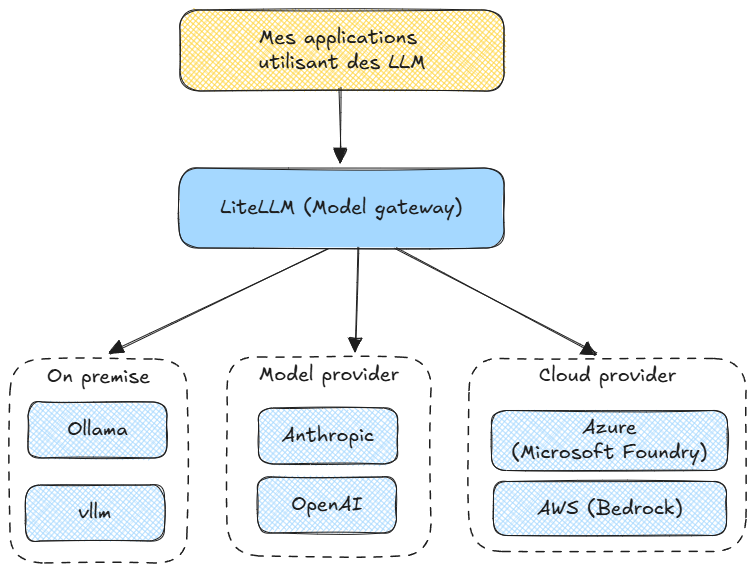
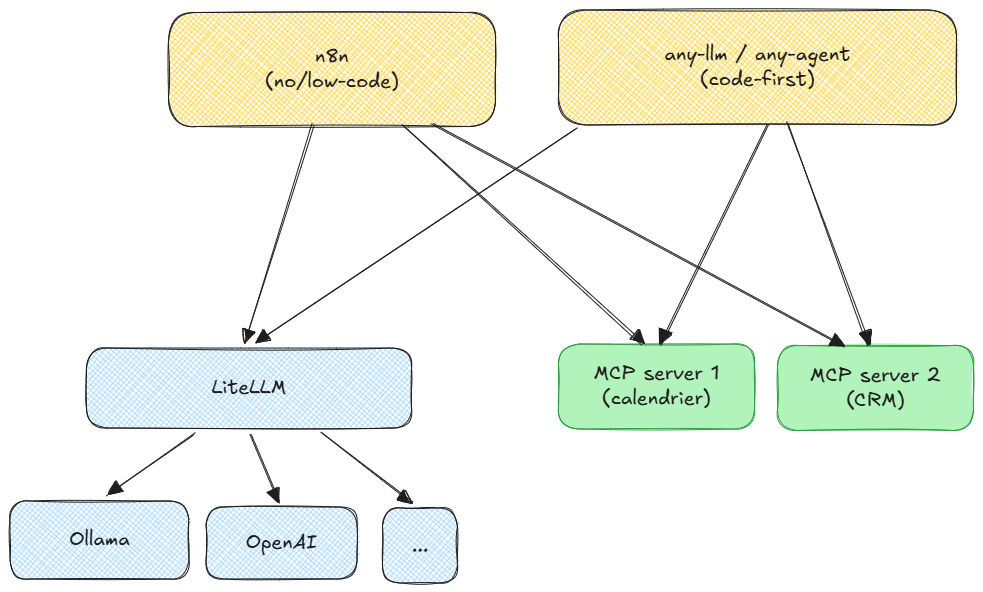
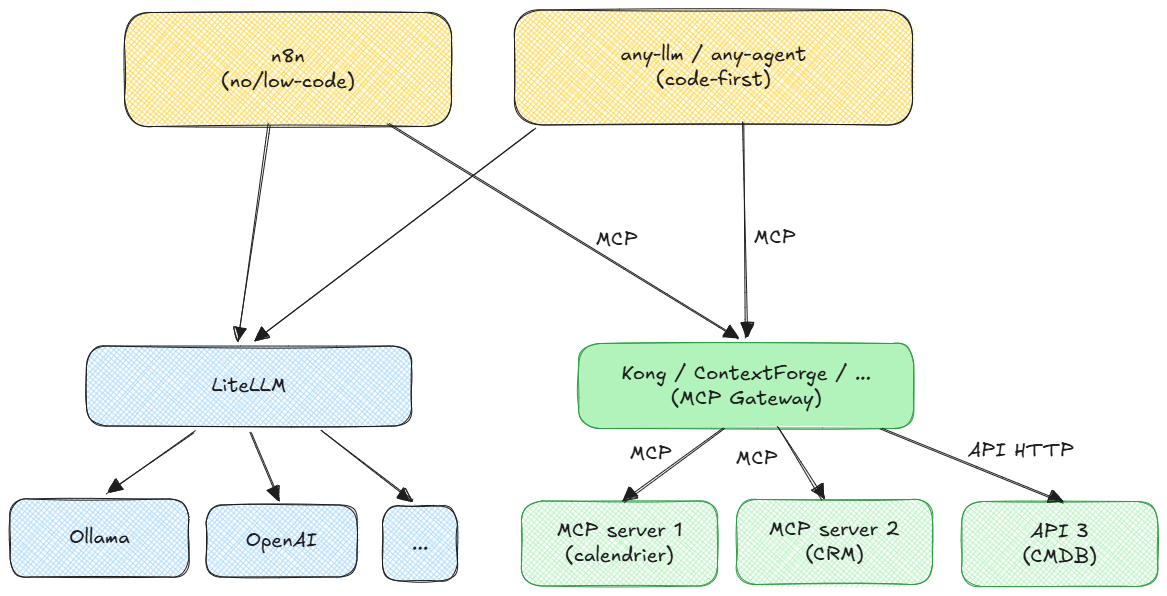
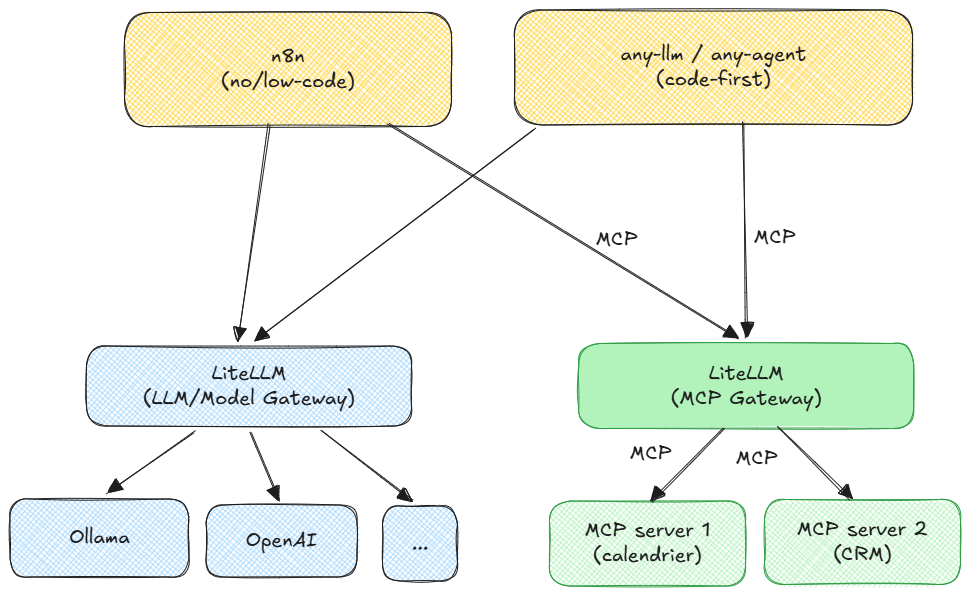
Si vous répondez oui à chaque étape, alors oubliez les solutions miracles propriétaires et figées. Dans le monde de l'IA, tout bouge beaucoup trop vite, et rien de neuf pour répondre à ça : il va falloir penser architecture modulaire pour rester paré à toute éventualité. Le secret ne réside pas dans le choix du meilleur modèle actuel, mais dans la façon dont vous assemblez vos composants pour rester indépendant.
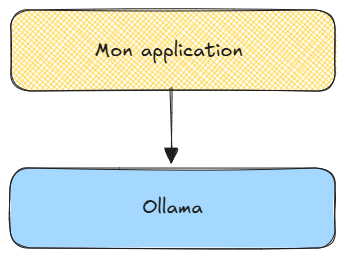
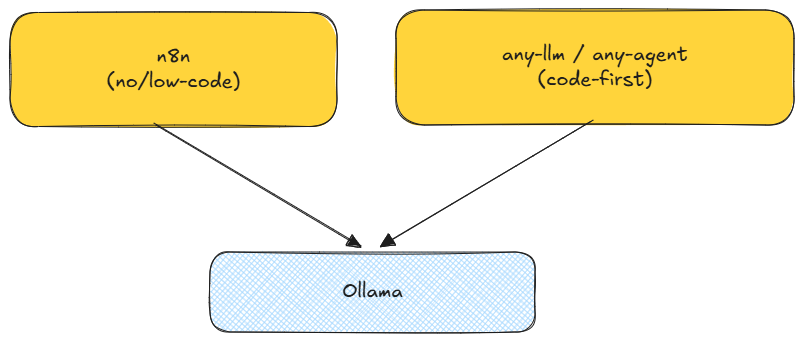
C'est le principe d'une architecture en couches : chaque composant a une responsabilité unique, ils communiquent via des interfaces standardisées, et on peut en remplacer un sans tout reconstruire.
Nous allons en explorer quelques-uns, qui devraient vous permettre de vous sentir plus serein pour la suite, enfin, au moins pour 6 mois...